【论文笔记】ArcFace--Additive Angular Margin Loss for Deep Face Recognition(CVPR 2019)
 pdf、code
pdf、code
发表于CVPR 2019【这里阅读的版本是2022/9/4日更新的】,[被引3769]
- 提出了Additive Angular Margin Loss,将loss函数转换到了超球面上,增加了可解释性,也提高了模型的辨别能力
- 最后的结果达到了SOTA的效果,在有噪声的数据中依然表现很好,有很好的鲁棒性(sub-center ArcFace*)
- 对网络结构没有做出修改(实验中一般使用ResNet网络)
- 还可以用来合成图像*
*表示是论文更新后新加的
背景介绍
Face Representation的目标是提取出对齐后的人脸的特征,达到有小的类内(intra-class)距离,和大的类间(inter-class)距离。目前有两类方向:
- 训练分类器:常用基于softmax损失函数的分类器
- 直接学习一个嵌入(embedding):triplet损失函数(如Google的FaceNet)
缺点在于都是依赖大规模的数据和复杂的网络结构
基于softmax loss的缺点:
- 学习到的特征对于闭集分类问题是可分离的,但对于开放集人脸识别问题的区分度不够
- 线性变换矩阵$W$的大小会随着$N$线性增长
基于triplet loss的缺点:
- 人脸三元组的数量会急速增长
- semi-hard的样本挖掘问题比较困难
ArcFace使得DCNN特征和最后一个全连接层的点积等于特征和中心归一化后的余弦距离。并且引入了sub-classes(sun-center ArcFace),减小intra-class距离的限制,这样有噪声的图像会更靠近某个类的sub-class(有数据清洗的功能),不会严重影响整个模型的训练。
相关工作
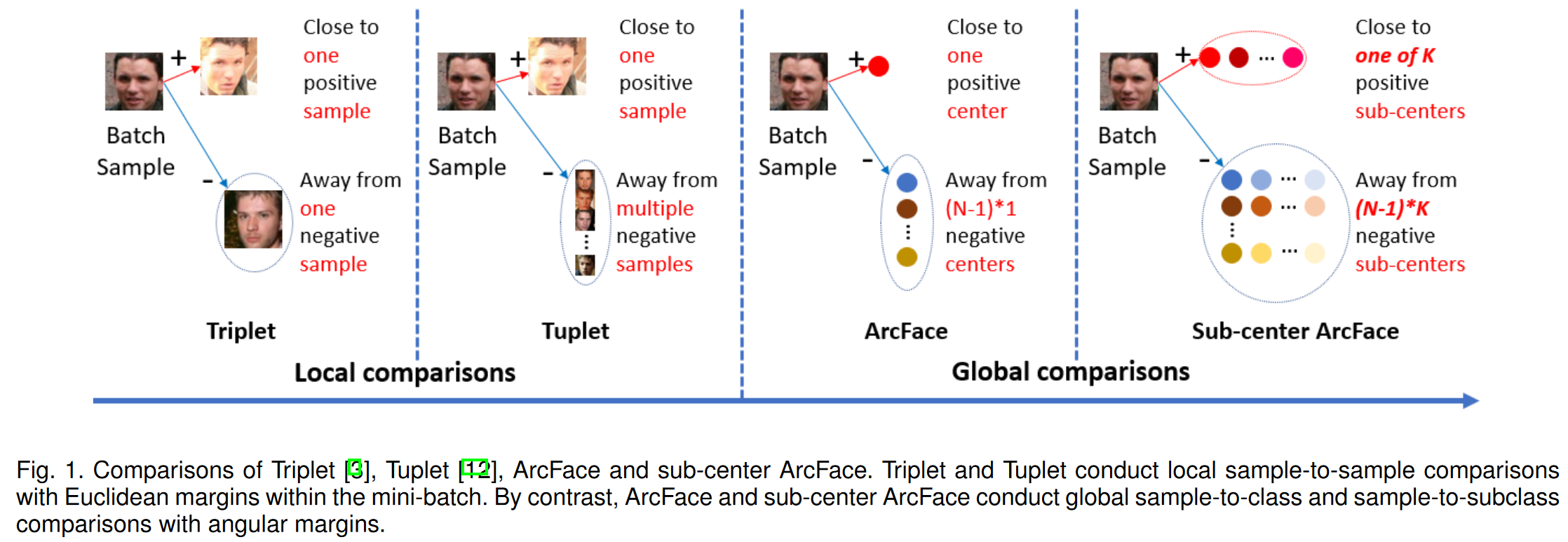
triplet loss: FaceNet
margin based softmax loss: Sphereface, Cosface
在margin based softmax的基础上探索自适应参数 (P2sgrad, Adacos, Adaptiveface)、类间正则化 (Regularface, Uniformface)、挖掘 (Curricularface)、分组(Groupface)等
基于边际(margin)的 softmax 方法以保持每个类的中心的内存消耗为代价进行全局比较
人脸数据集一般都存在噪声图像,所以也有很多研究聚焦于处理噪声图像的问题
ArcFace的原理
[注]本文中将embedding feature dimension嵌入特征维度设置为了512,即$x_i∈\mathbb{R}^{512}$
基本的ArcFace
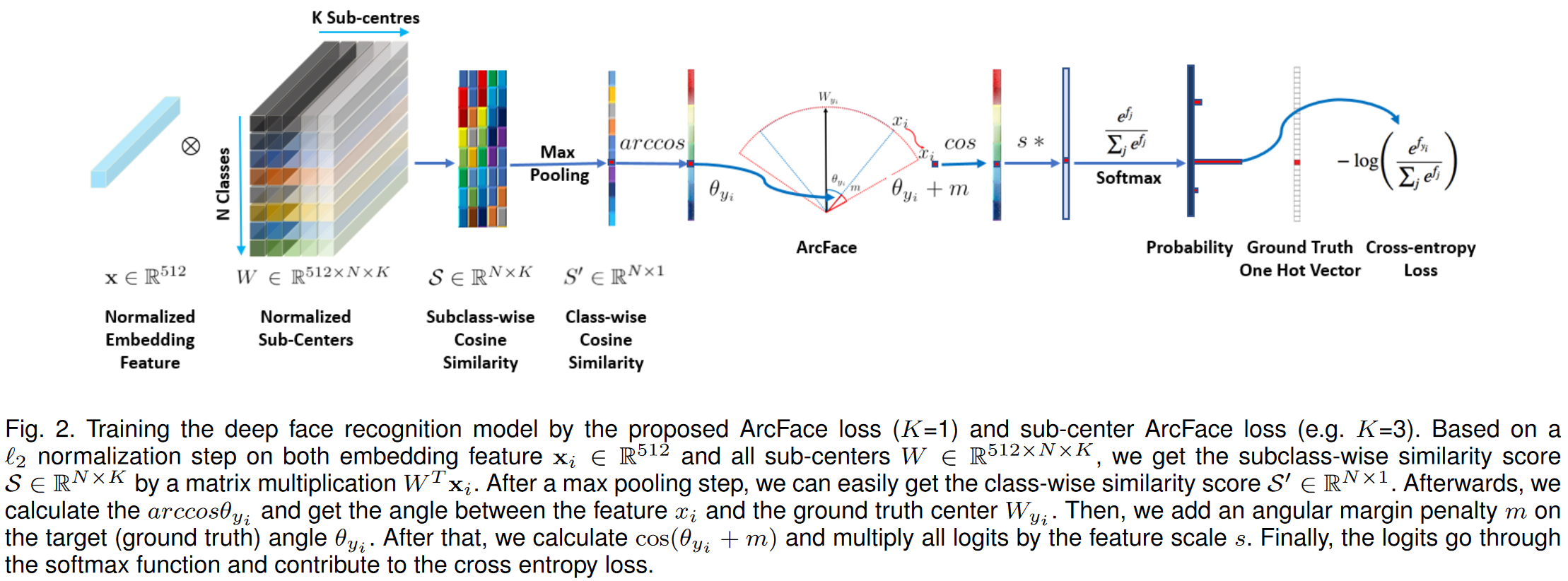
ArcFace参考了Sphereface将偏重bias设置为了0($b_j=0$)。
原始的softmax函数:
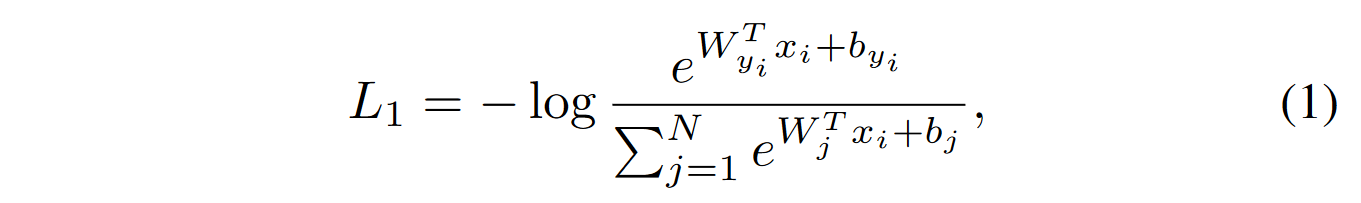
将logit变了一下形: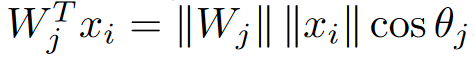 ,其中$\theta_j$是$W_j$和$x_i$之间的角度($\theta_j=arccos(W^T_{j}x_i)$)。参考Sphereface和Cosface用$L_2$正则化(即$L_2$范数)将$||W_j||$固定到1。又参考了Cosface、Normface等,用$L_2$正则化特征$||x_i||$,将其缩放到s。对$W$和$x$的正则化使得loss只和$W_j$和$x_i$之间的角度有关了。(样本$x_i$属于第$y_i$类)
,其中$\theta_j$是$W_j$和$x_i$之间的角度($\theta_j=arccos(W^T_{j}x_i)$)。参考Sphereface和Cosface用$L_2$正则化(即$L_2$范数)将$||W_j||$固定到1。又参考了Cosface、Normface等,用$L_2$正则化特征$||x_i||$,将其缩放到s。对$W$和$x$的正则化使得loss只和$W_j$和$x_i$之间的角度有关了。(样本$x_i$属于第$y_i$类)
又引入了$x_i$和$W_{y_i}$之间的angular margin penalty角度余量惩罚$m$,来同时增强intra-class的紧凑性和inter-class差异(利用了$x_i$在超球面上是分布于类中心周围的。
于是ArcFace的损失函数如下所示:
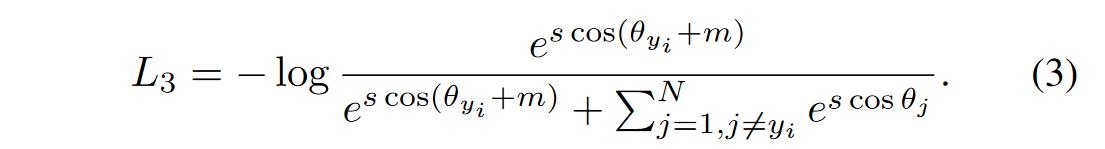
==角度余量惩罚是如何计算的呢==貌似是个超参数,要事先定义好
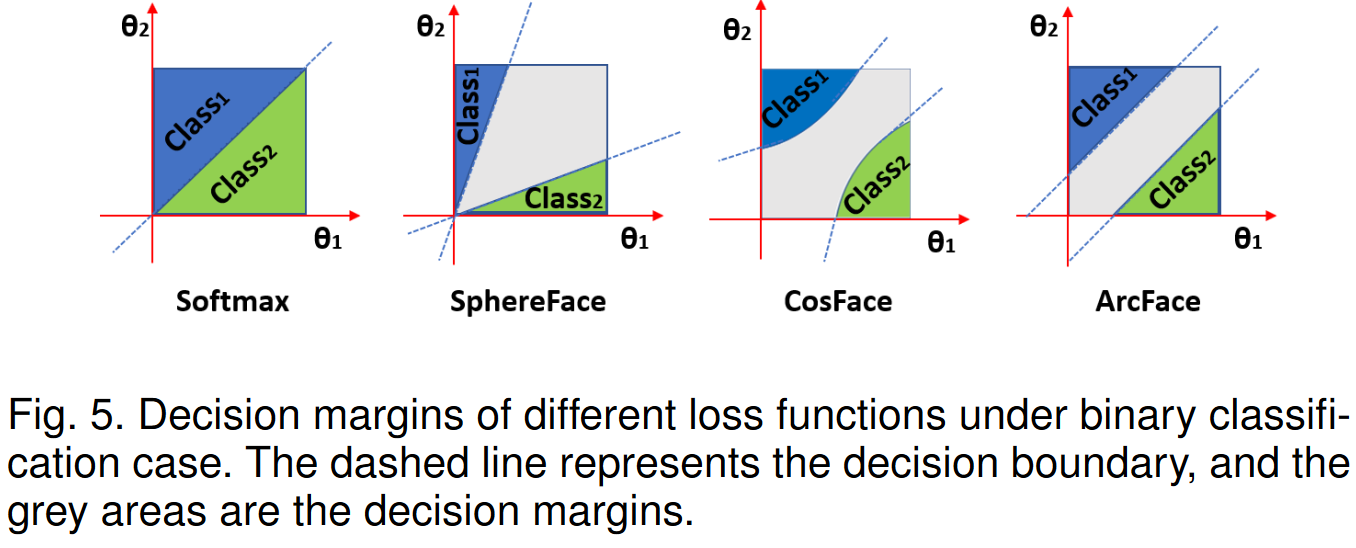
对比
SphereFace, ArcFace, 和 CosFace提出的是3种不同的margin penalty。在数值上,三者差距不大,混合使用也可以有很好的结果。然而,在几何上,ArcFace有更好的几何属性。下图是一个二分类问题上的演示,ArcFace有恒定的线性角度余量
引入Sub-Class的ArcFace
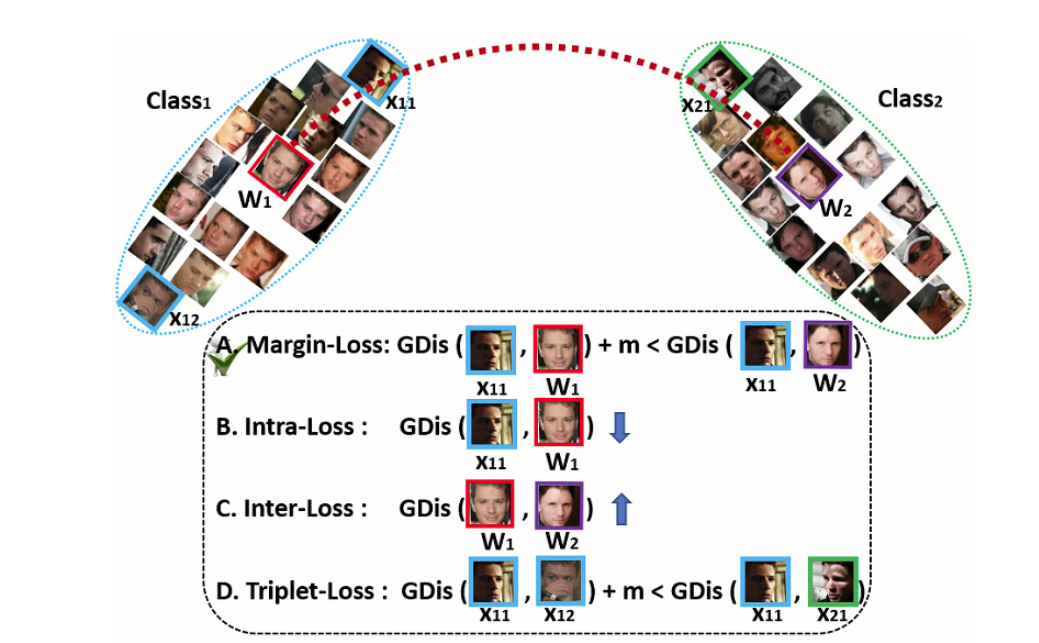
引入sub class是为了抵御数据中可能存在的噪声,增强模型的鲁棒性。
为每个身份设置K个sub class。计算子类相似度$\mathcal{S}∈\mathbb{R}^{N\times K}$,$\mathcal{S}=W^T\times x_i$。然后对$\mathcal{S}$进行一个最大池化操作,计算出类别相似度$\mathcal{S’}∈\mathbb{R}^{N\times 1}$
sub-center ArcFace的损失函数如下所示:
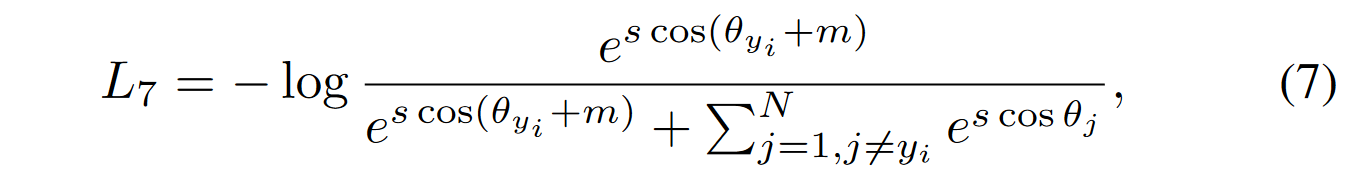
其中,
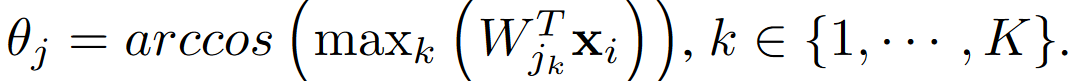
(这里和ArcFace的区别就在于$\theta_j$的计算,这里取的是和K个sub-center的最大角度。而在ArcFace中,$\theta_j=arccos(W^T_{j}x_i)$)
如下图所示,可以聚集图像,周围小的就是sub-class,有些空的,因为可能不需要这么多。噪声图像就被过滤出来了。(p.s.设置$K=10$时,这包括了真正的中心,也就是说非中心的sub-class有9个)所以可以用ArcFace来过滤掉噪声图像,通过设置阈值,如angle ≥ 77◦ or cosine ≤ 0.225)

引入sub-class的代价是intra-class距离会被拉大,因为噪声图像会离中心很远。直接的办法是图像聚集后(可以明显区分出主导中心后,这时,模型就有了足够的区分能力),直接把偏离主导中心的样本去掉,这样就可以减小intra-class距离,重新获得类内紧凑性了。
Inversion of ArcFace
这节讲述用ArcFace的损失梯度和面部统计先验(存储在BN层)来重建身份保留以及视觉上可信的面部图像。(这是说明了ArcFace还可以用来生成图像,和人脸识别关系不大)
实验结果
在实验中使用了特定种族的注释器
用的训练数据为CASIA, VGG2, MS1MV0和Celeb500K。用sub-class ArcFace来清理噪声图像,得到IBUG-500K, including 11.96 million images of 493K identities:
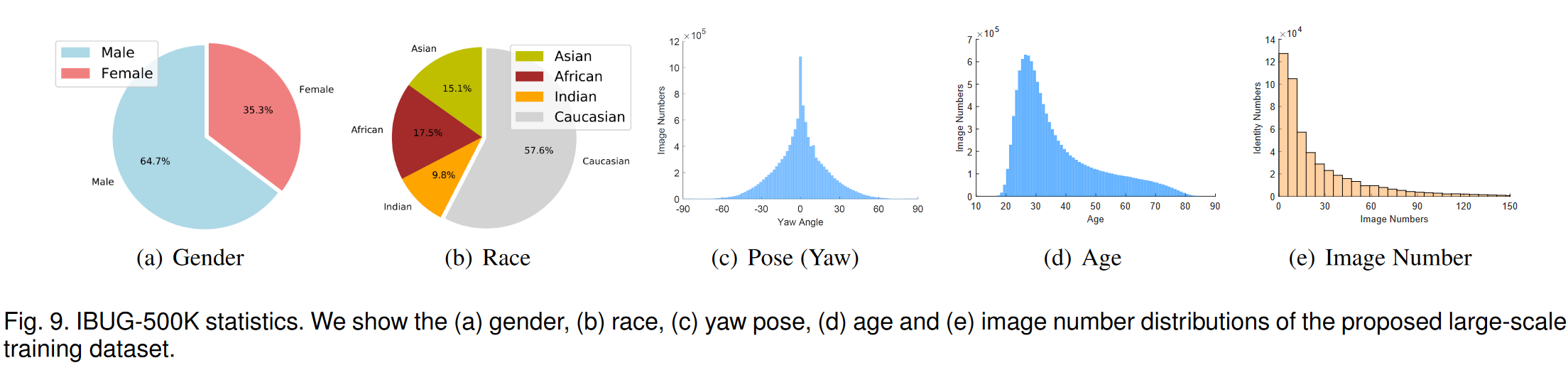
测试数据有LFW, CFP-FP, AgeDB, CPLFW and CALFW, MegaFace, IJB-B, IJB-C and LFR2019-Image等等
采用了和Sphereface、CosFace的一样的人脸对齐方式,利用 RetinaFace 预测的五个面部点来截取人脸(五点)(“Retinaface: Single-shot multi-level face localisation in the wild,” in CVPR, 2020)(一开始很疑惑,2019年的论文怎么引用了2020CVPR的文章,原来这个版本是2022年更新的)原版也是用5点来对齐,但是没有用RetinaFace
使用的网络结构是ResNet50和ResNet100,训练ArcFace时使用SGD optimizer来
设置feature scale $s=64$, angular margin $m=0.5$,嵌入特征维度设置为了512。用MXNet来实现的实验
After the last convolutional layer, we explore the BN [13]-Dropout [29]-FC-BN structure to get the final 512-D embedding feature???
其他相关知识(待补充)
为什么要特征缩放
因为当特征值有相似的范围的话梯度下降会比较快。
深度学习、人脸识别算法
Cosface: Large margin cosine loss for deep face recognition, in CVPR, 2018.
Sphereface: Deep hypersphere embedding for face recognition, in CVPR, 2017
Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems
复现时可以参考的资料
【论文笔记】ArcFace--Additive Angular Margin Loss for Deep Face Recognition(CVPR 2019)