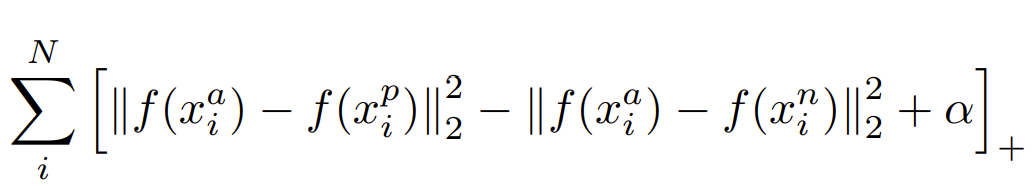人脸识别门禁系统调研
主要参考了四川大学一位博士的一篇毕业论文《高精度三维人脸识别技术及其门禁应用研究》中绪论及参考文献部分https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CDFD&dbname=CDFDLAST2022&filename=1021831289.nh&uniplatform=NZKPT&v=_CBMr2TIM4vECiK5CMJl0-VVf_M43nxrDEHrIj8VNBPFDF1AhJp9GCKcFnJK-09P
二维人脸识别
【原理】对人脸的纹理数据进行特征表达,通过判断特征间的相似度来对人脸进行身份确认
【缺点】易受人脸姿态、妆容、环境光照等的影响,应用受限制
三维人脸识别门禁
【优点】
抗环境因素、人脸姿态因素、人脸化妆因素等
【原理】
需要有数据采集、人脸识别、人脸防伪过程。
人脸识别技术通过数据采集前端抓取通行人员的图像信息,利用人脸检测算法获取人脸区域,并使用人脸识别算法模型对人脸区域图像进行特征表达,最后通过特征之间的相似度比较完成对通行人员的身份鉴定。人脸防伪使用人脸防伪模型对通行人员人脸数据是否为真人进行分类,进而完成对通行目标的是否为真人的判断。
基于深度学习的人脸识别
通常的方法是对人像图像进行特征表达,在模型定义好的特征空间中根据特征间的距离计算出特征间的相似度,进而确定样本的人物身份。基于深度学习的人脸识别一般利用有监督的学习方法使用CNN对算法进行建模。使用迁移学习,使模型能够适应新的数据分布。
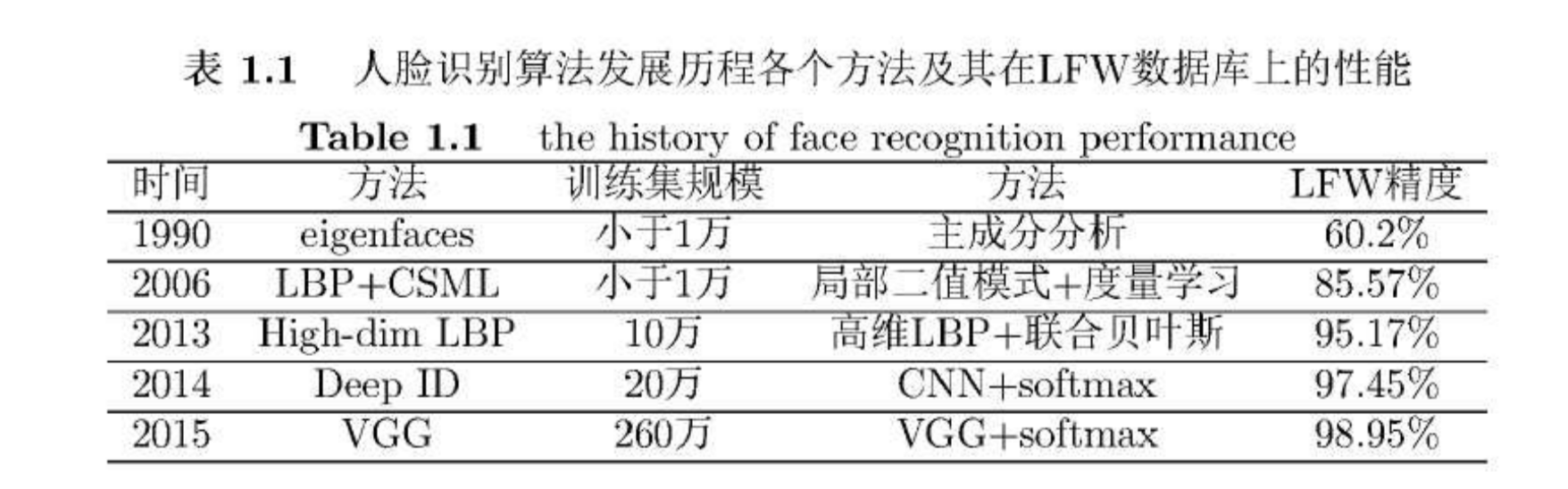
深度学习的人脸识别算法有:DeepID (香港中文大学)、DeepFace (Facebook)、FaceNet (Google)、VGGFace(牛津大学)
DeepFace:
使用了三维模型来进行人脸对齐,然后使用深度卷积神经网络对人脸对齐后的人脸图像各个Patch进行分类学习,并使用经典的交叉熵损失函数对模型进行优化监督。
DeepID系列
- DeepID:使用卷积神经网络对人脸进行表示,提取出其特征,使用softmax损失函数。其算法优化的主要手段就是增大数据集(对齐图片的预处理(增大数据集),再基于弱对齐图像从10个区域、3种尺度、RGB和灰色2种通道方面截取出60个面部块,分别输入单独的ConvNet,将从中提取特征。)检测的关键点是使用Sun等人提出的面部点检测方法检测5个面部标志点,包括两个眼睛中心,鼻尖和两个嘴角。
- DeepID2:依然使用卷积神经网络对人脸进行表示,在损失函数上添加了验证信号(人脸识别信号和人脸验证信号),两个信号使用加权的方式进行了组合。。根据全局对齐的人脸和人脸标志点的位置,裁剪了400个patch,用200个ConvNet提取出400个特征。
- DeepID2+
- DeepID3:提出了2种深度神经网络框架(一个基于VGG,一个基于GoogLeNet,含有Inception层),监督信号作用于中间层和最后层。
FaceNet:
并没有2维和3维之间的对齐。使用GoogLeNet V1模型,冰使用三元组损失函数代替之前的交叉熵损尖函数,在一个超几何球空间上完成优化任务,使得类内距离更紧凑,类间距离更远。
这三种算法的详细介绍见后
VGGFace:人脸分类器使用VGGNet+Softmax loss,输出2622个类别概率,这是预训练过程。三元组学习人脸嵌入使用VGGNet+Triplet loss,输出1024维的人脸表示。在人脸分类器基础上,用目标数据集用fine-tuning方法学习了映射层。人脸验证则是通过比较两个人脸嵌入的欧式距离来验证同种人。
Center-Loss人脸识别 很好的特征收敛性能
46 立体视觉法
人脸防伪
除了要鉴定人脸对应的人物身份,还要人脸防伪,即鉴别是否是真实人脸(尤其要抵抗现在3D打印的、仿真度极高的三维面具)

在基于深度学习的人脸识别中,有CNN结合LSTM的方式使用多帧数据输入模拟LBP-TOP的方法。
三维人像的数据采集
使用三维人脸照相机采集人脸数据,有直接的三维深度传感器,还可以使用三维重建算法对二维图像进行三维重建。三维人脸重建技术分为被动和主动2种
三维重建算法有基于纹理信息的、基于纹理阴影信息的、基于统计模型的、立体视觉法(研究最多、应用最广泛)
近年来,基于结构光的三维测量技术也已经广泛应用于商业产品中。
三维人脸采集的设备,比较著名的有美国Artec3D、3dMD、FARO等,国内有北京天远、讯恒图像、技睿新天、杭州先临等。
基于深度学习的人脸识别相关研究
【Facebook】DeepFace: Closing the Gap to Human-Level Performance in Face Verification
发表于CVPR 2014,深度学习人脸识别的开山之作,主要用于人脸验证
https://www.cs.toronto.edu/~ranzato/publications/taigman_cvpr14.pdf
参考了CSDN上的博客:https://blog.csdn.net/DL_wly/article/details/92850494
人脸识别的一般流程为:检测——对齐——表示——分类
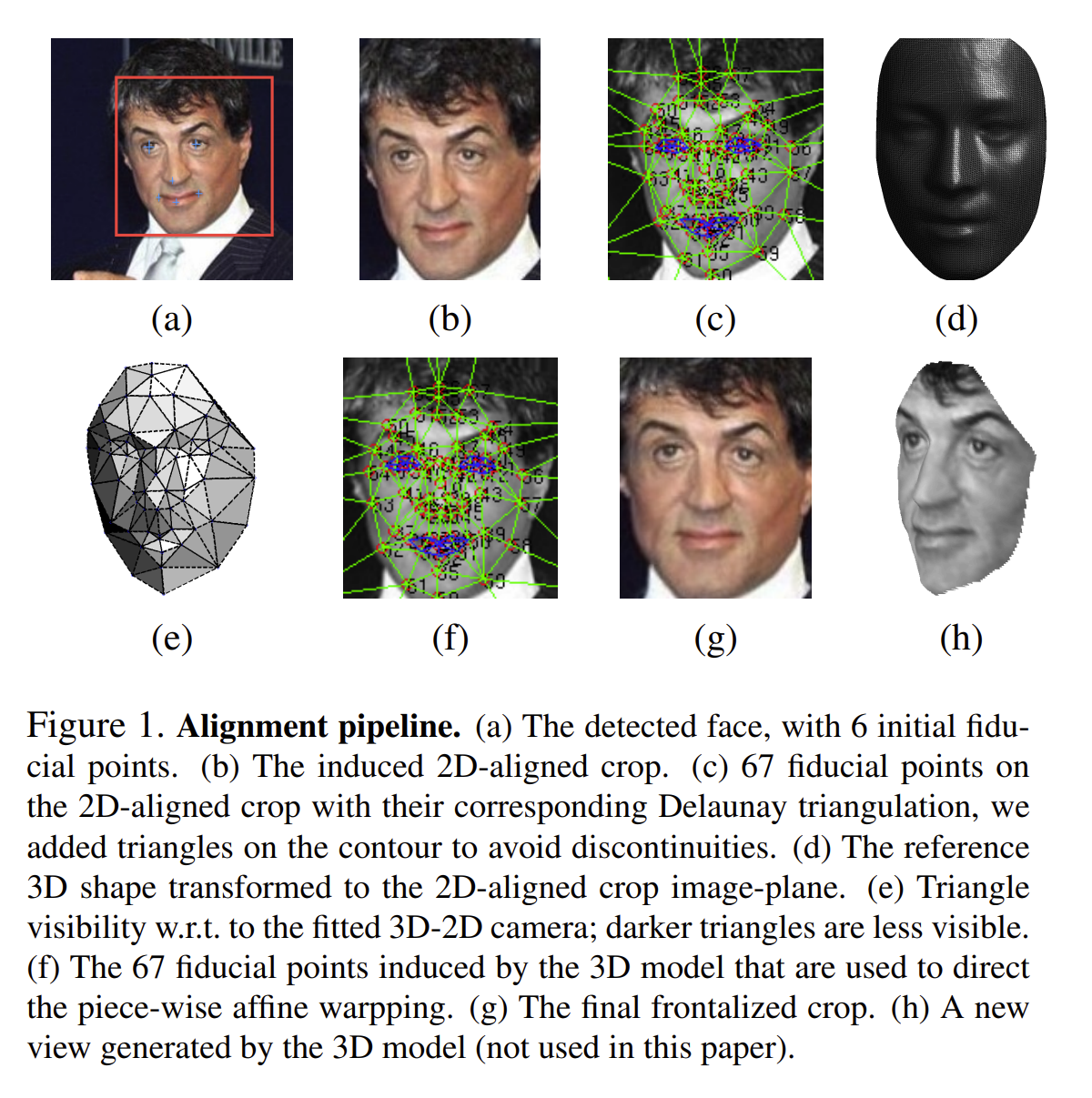
在人脸对齐过程中,DeepFace提出了新的方法:
- 用LBP(Local binary patterns, 局部二值模式)+SVR(Support Vector Regression,支持向量回归)的方法检测出人脸的6个基准点,眼镜两个点,鼻子一个点,嘴巴三个点,如下图(a)
- 通过拟合一个对基准点的转换(缩放,旋转,平移)对图像进行裁剪,得到下图(b)
- 对图像定位67个基准点,并进行三角剖分,得到下图(c)
- 用一个3D人脸库USF Human-ID得到一个平均3D人脸模型(正脸),如图(d)
- 学习一个3D人脸模型和原2D人脸之间的映射P,并可视化三角块,如图(e)
- 通过相关的映射,把原2D人脸中的基准点转换成3D模型产生的基准点,得到如图(f)所示,最后的正脸就是图(g)。
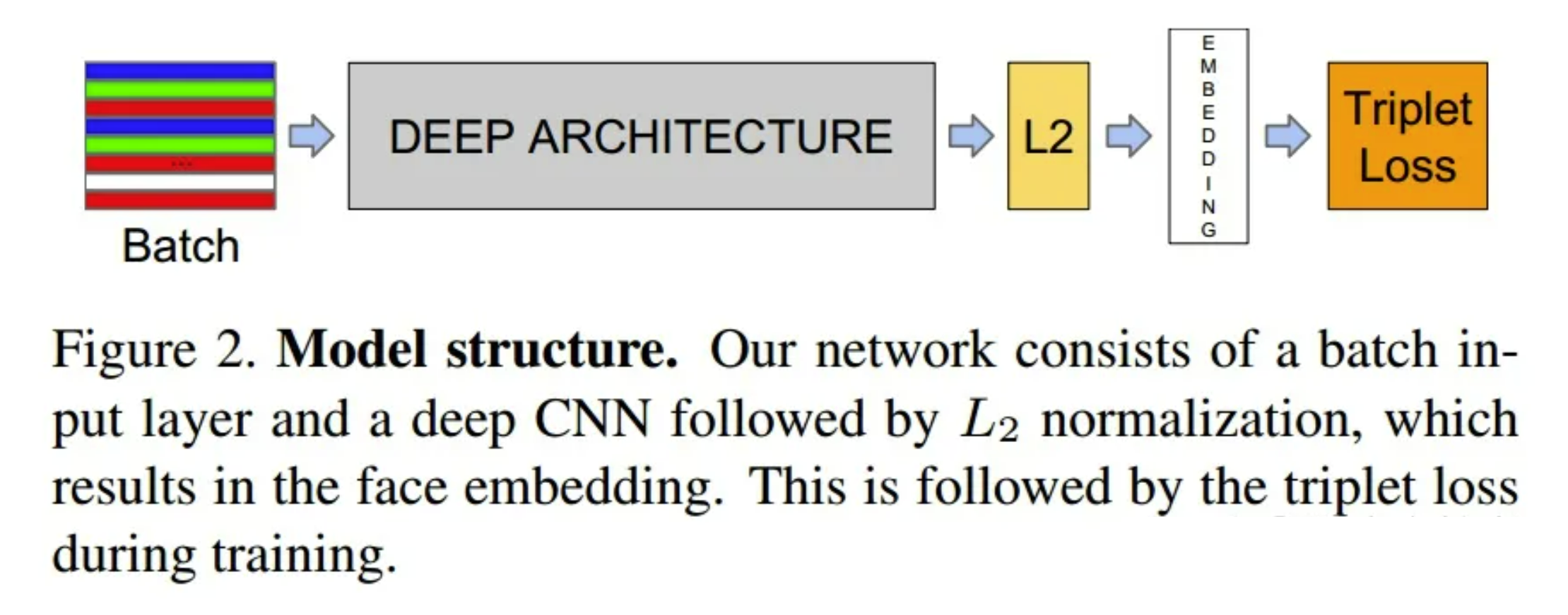
在人脸表示过程中,如下图所示,训练了一个DNN来提取人脸图像的特征表示
C1和C3表示卷积层,M2表示最大池化层,“32x11x11x3@142x142”表示使用32个大小为11x11x3的卷积核,输出feature map的大小为142x142。前三层主要提取低水平特征,其中最大池化可以使输出对微小的偏移更加鲁棒(可能人脸对齐歪了一些也没关系),因为最大池化会损失信息所有没有使用太多。
L4,L5,L6是局部卷积层,对于feature map上每个位置,学到不同的卷积核(即一张feature map上的卷积核参数不共享),因为人脸的不同区域会有不同的统计特征,比如眼睛和眉毛之间的区域比鼻子和嘴巴之间的区域具有更高的区分能力。局部卷积层会导致更大的参数量,需要很大的数据量才能支撑的起。
F7和F8是全连接层,用来捕捉(不同位置的)特征的相关性,比如眼睛的位置和形状,和嘴巴的位置和形状。F7层的输出提取出来作为人脸特征,和LBP特征对比。F8层的特征喂给softmax用于分类
对F7层的输出特征进行归一化(除以训练集上所有样本中的最大值),得到的特征向量值都为0到1之间

后面三层都是使用参数不共享的卷积核,之所以使用参数不共享,有如下原因:
- 对齐的人脸图片中,不同的区域会有不同的统计特征,卷积的局部稳定性假设并不存在,所以使用相同的卷积核会导致信息的丢失
- 不共享的卷积核并不增加抽取特征时的计算量,而会增加训练时的计算量
- 使用不共享的卷积核,需要训练的参数量大大增加,因而需要很大的数据量,然而这个条件本文刚好满足。
【Google】FaceNet
使用Triplet Loss(三元组损失函数)作为损失函数,基于GoogLeNet或Zeiler&Fergus模型,直接学习从人脸图像到紧凑的欧几里德空间的映射,提取的嵌入特征。将提取到的特征进行L2 normalize,得到embedding结果(即一张图片使用128维向量表示)。再将得到的embedding结果作为输入,计算triplet loss。
Triplet Loss的定义如下。Triplet 三元组指的是:anchor, negative, positive 三个部分,每一部分都是一个 embedding 向量。其中anchor指的是基准图片,positive指的是与anchor同一分类下的一张图片,negative指的是与anchor不同分类的一张图片。训练目标:anchor与positive的距离比anchor与negative的距离小(相似度高)