
【论文笔记】Membership Inference Attacks Against Machine Learning Models (ICMP 2017)
研究成员推理攻击(Membership Inference Attack, MIA):目标模型作为black box,要求判断某一条data record是否是用于训练该模型的数据。并探讨导致泄露的因素
本文主要针对有监督训练的模型,提出了shadow training的技术来为训练攻击模型构造数据集:
首先,利用训练目标模型的API训练若干shadow models,模仿目标模型的行为
接着,用训练好的shadow models来为attack model构造训练集数据、测试集数据(解决了目标模型是black box的问题,对预测向量的数据增强效果)
最终,attack model实现判断是否是训练集的二分类问题攻击的实现主要是利用了目标模型在其训练集和非训练集上的输出行为差异,这一般由于训练时发生了过拟合导致,但其根本原因在于存在accuracy gap(模型在训练集和测试集上准确率的差异,对每个类别来说)
1 Introduction
目前商用的机器学习模型都是以a black-box API的形式来提供服务(例如根据用户喜好训练的推荐模型等等)。本实验通过训练一个攻击模型来实现成员推理攻击,通过区分目标模型对于训练数据和非训练数据的不同输出行为。
当模型是一个black box时,模型的结构、参数就是不可知的了(是white box时就是都知道的,之前2篇论文中都是以white box的形式来访问)
为了更好地实现攻击,引入了shadow training的技术:首先,创建多个模仿目标模型行为的“shadow models”,但这些模型的训练数据集是已知的,因此知道这些数据集中成员关系的基本真相。再用这些标记的输入和shadow models的输出来训练攻击模型
注意和model inversion的区别:model inversion是为了重建训练数据,或者从模型中得到某些class的属性、特征。而membership inference是为了判断某个数据是否是用于训练该模型的数据。也就是说,model inversion不关心单个数据record
2 Machine Learning Background
商用的训练模型由厂商选择,可能只基于自己的验证子集来设置模型的结构,那么在用户自己的数据集上训练时,很可能产生过拟合。即使现在有很多使用正则化来解决过拟合问题的方法,但是在商用模型中很少会控制正则化。
过拟合就会导致训练数据和非训练数据之间有明显差异
3 Privacy in Machine Learning
定义了研究的对象membership inference,强调了和model inversion之间的区别
抵御membership inference attack是为了保护个体的隐私安全。而抵御model inversion是要保护一整个类的隐私信息(本文中认为model inversion很难抵御,例如某个疾病和某个基因有关,那么判断出有这种疾病就可以推断患者的这个基因,即class的特征是必然会被模型的判断结果所泄露的)
本文研究的membership inference attack是要评估一个人的membership risk,即若他的个人数据被用来训练一个模型(如推荐系统),是否会泄露其个人信息
4 Problem Statement
描述了研究的问题,前提假设条件
针对分类模型
假设敌手可以获得输出的prediction vector(在每一个类别上的打分);知道输入输出的形式、取值范围、知道模型的结构、算法或者可以访问训练模型的learning oracle(二选一,后者不知道具体的参数、结构);知道训练集分布的背景知识(如有相同的分布的不相交子集、或者知道其边际分布
批判标准:precision(精确率,判断为真的中有多少是对的)和recall(召回率,多少真的被判断为真的了)
5 Membership Inference
具体的攻击方法
A. Overview of the attack
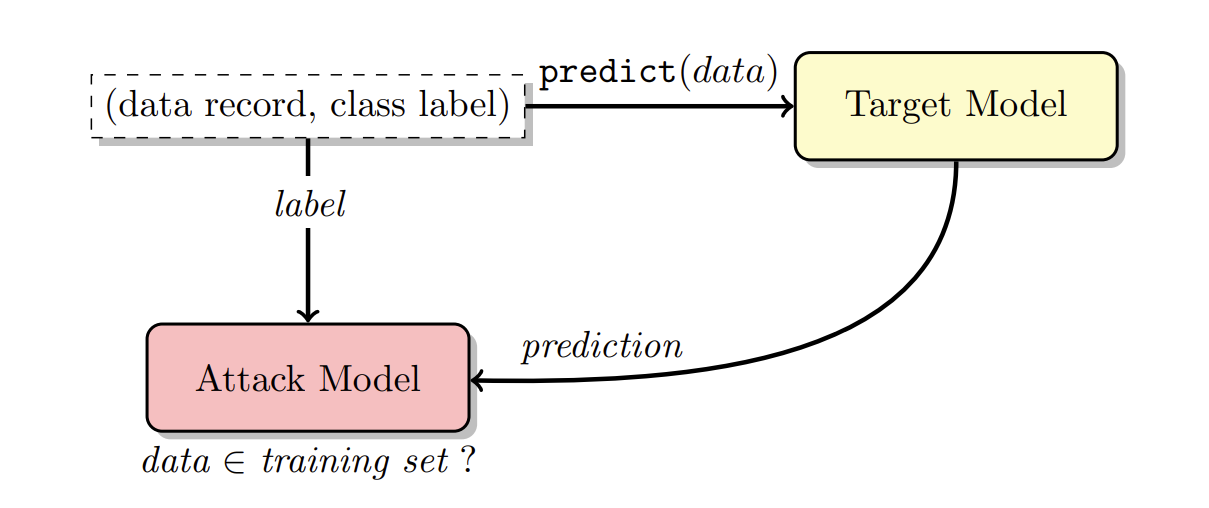
B. Shadow models
攻击者要创建$
k
$个shadow model $f^{i}_{shadow}()$,训练的数据集为$D^{train}_{shadow^i}$(和目标模型的数据集的分布相似,但是不相交。虽然在商业模式下的目标模型的训练算法和结构不可知,但是可以同样利用这个商业服务来训练shadow model(如下图所示,其中$train()$就是服务商提高的API)
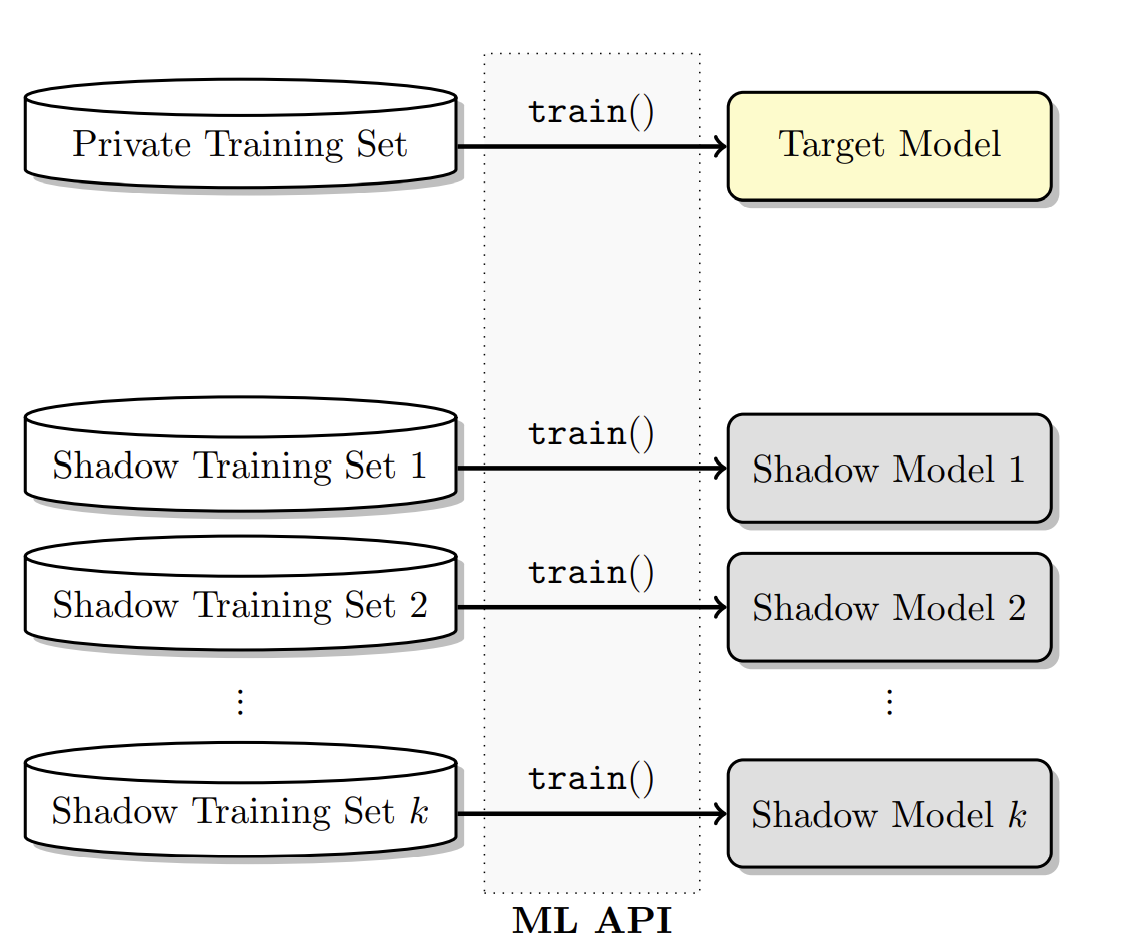
shadow model越多,攻击模型的准确度就越高。那么接下去的问题就是用于训练shadow model的数据$D^{train}_{shadow^i}$如何而来
C. Generating training data for shadow models
介绍了几种生成目标模型训练集分布接近的数据集的方法
Model-based synthesis(使用目标模型来构造数据集)
分为2个阶段
(1)用hill-climbing算法$search$可能数据的空间,即随机生成$x$,选择其中得分高的(针对具体的某个类c)
(2)从上述数据集中$sample$合成的数据
在$search$(迭代过程)时,设置了$j$来记录失败次数,$k$用来控制围绕被接受的记录的搜索直径,以便提出新的记录(每次提出新的x时,只替换k个特征,即搜索半径)
当$x$的评分向量$y$中$y_c$最大(表明这个$x$是$c$类的),而且$y_c$超过了预先设定的指标$conf_{min}$,那么就选择这个$x$

Statistic-based synthesis
若敌手知道训练集的统计信息,那么直接从这个分布中合成数据即可
Noisy real data
若敌手可访问和训练集类似的数据集,然后随机反转其中10%或20%的特征,就可以作为训练shadow models的数据集了
D. Training the attack model
主要的思想就是在相似的训练集上以相同方式训练的模型,其行为是相似的
给shadow models一系列输入,得到其相应的输出,若是shadow model对应的训练集中的数据,就标记为$in$,若不是,则标记为$out$。这些记录用于训练attack model,并分成$c_{target}$个划分,分别对应目标模型的$c_{target}$个类别。
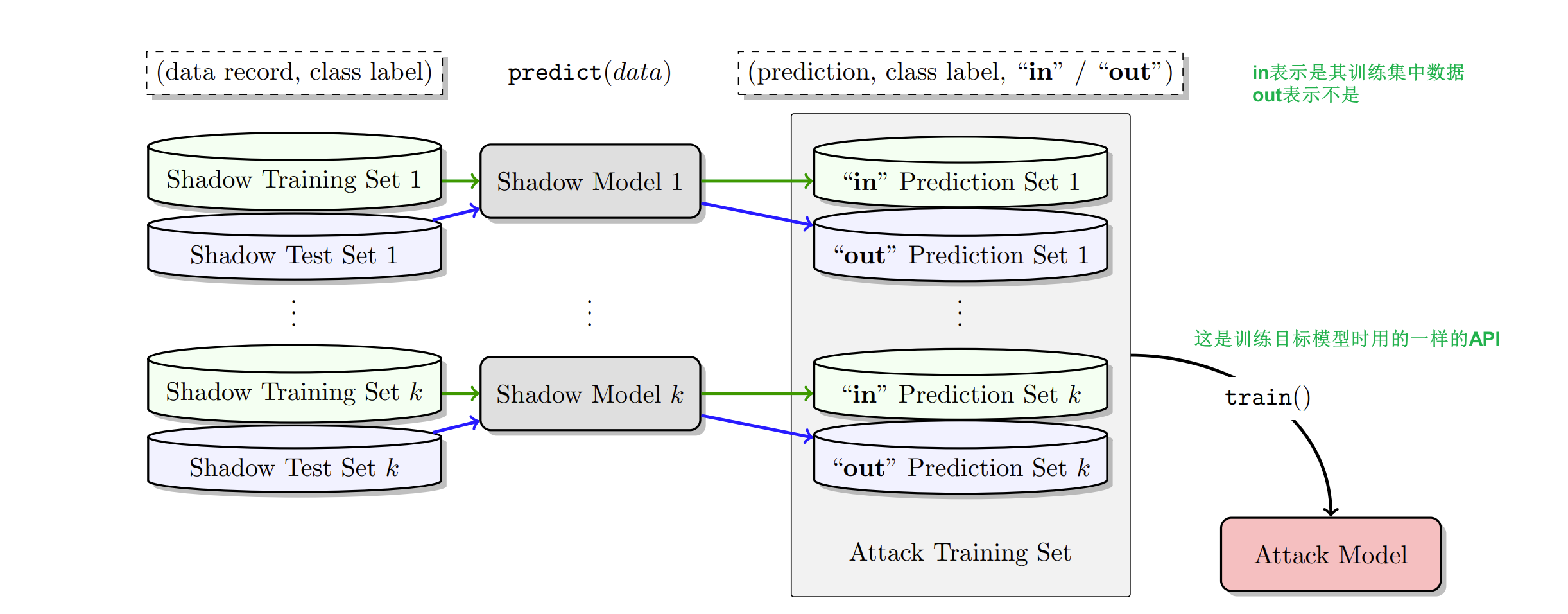
问询shadow models时用的测试集和训练集是不相交的(否则有歧义)
这里训练的attack model要解决的是二分类问题,所以任何适用于二分类问题的模型都可以(一般常用的模型,或者服务商提供的API都可以)
(感觉思想挺简单的,但是要实现比较复杂,有好多shadow models,而且训练shadow models时的数据集很重要)
6 Evaluation
介绍实验中使用的数据集、目标模型,展示实验结果
实验结果表明:本文所提出的攻击方法的鲁棒性很好,即使对目标模型的训练集的分布猜测有误,攻击的准确性还是很高。
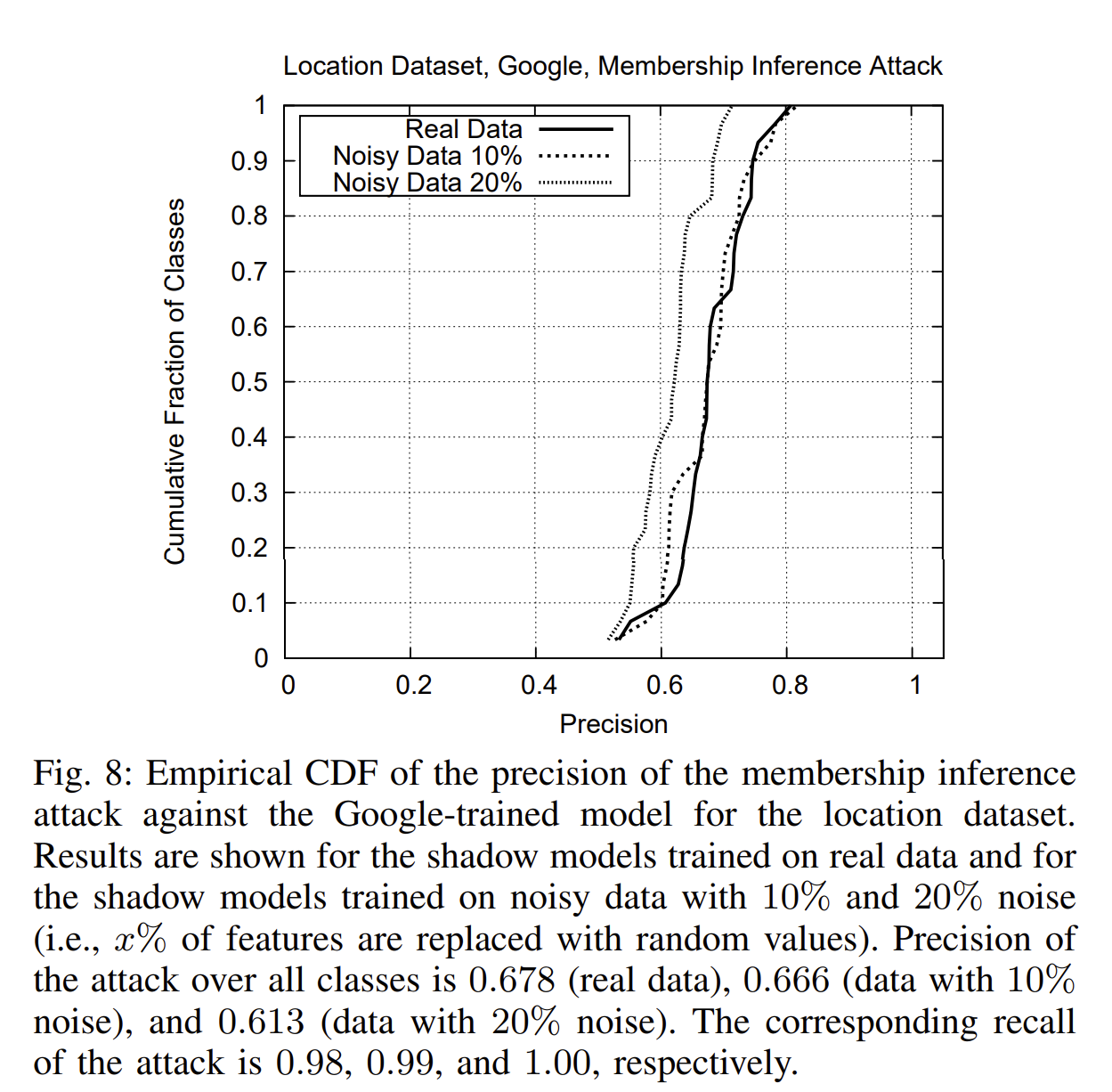
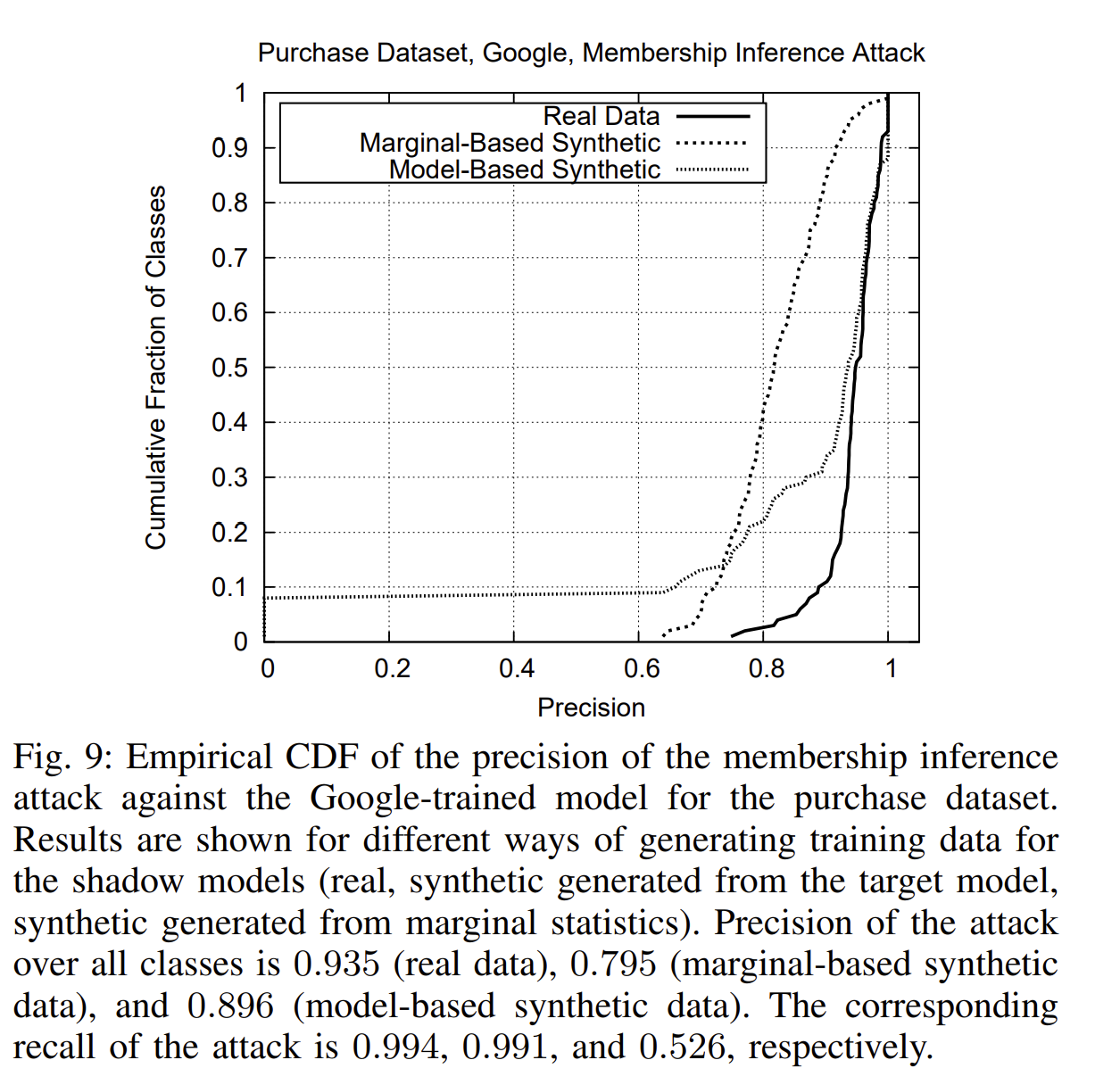
【!】当类的训练数据在整个训练集的比重较小时,攻击在这些类上的精确度(precision)上较低。
7 类的数量,和每个类的训练数据集对攻击的影响
类的数量越多,泄露的模型的内部状态越多。因为当数据集中类越多,目标模型就需要提取出更多特征、“记住”更多数据的信息来准确判断类别,所以也就会泄露更多信息。
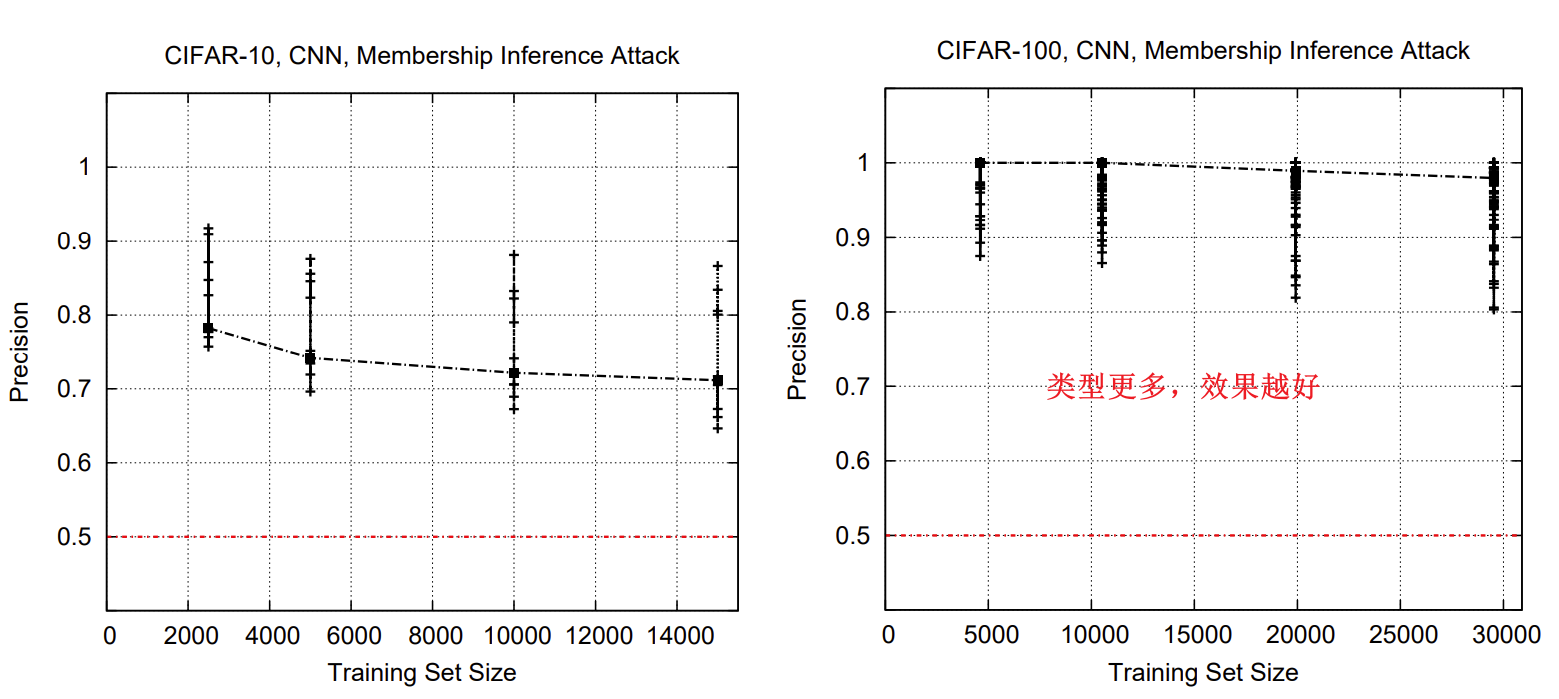
【???】
为什么这里说
“the more data in the training dataset is associated with a given class, the lower the attack precision for that class”
但是之前上面说“The reason for the attack’s low precision on some classes is that the target classifier cannot confidently model the distribution of data records belonging to these classes—because it has not seen enough examples.”
感觉有点矛盾?
过拟合对攻击的影响
同一种类的模型中,过拟合程度越大,模型泄露的信息越多。但是相同过拟合程度下,不同模型的信息泄露程度不一样。【!】所以,过拟合不是导致易受Membership Inference Attack的唯一原因。
模型结构中很重要的因素是accuracy gap(模型在训练集和测试集上准确率的差异,对每个类别来说)。当一个类别在某个模型中的accuracy gap越大,攻击在这类上的精确度(precision)越高。
毕竟MIA就是要区分目标模型在测试集和训练集上的行为差异,那么当accuracy gap越大,就说明二者的差异越大,攻击自然就越容易成功了,。
8 MIA成功的原因与抵御
MIA的成功与否与目标模型的普适性(generalizability)&训练集数据的多样性有关。
因为过拟合会显著导致易受MIA攻击,所以解决过拟合问题的方法是可以用来抵御MIA的。常见的方法由dropout()、Regularization(正则化)。
从训练过程角度,使用差异化的私有模型(differentially private models,就是和差分隐私有关的),这样一个模型是包含一条数据训练而得的概率和包含这条数据而得的概率相近,这样也可以用来抵御MIA。
从这些商用模型训练API的服务商角度,应该告知用户过拟合的风险、为数据集提供更加适合的模型结构等等。
A. Mitigation strategies
几种抵御MIA的策略如下
- Restrict the prediction vector to top k classes
- Coarsen precision of the prediction vector
- Increase entropy of the prediction vector
- Use regularization
根据作者的实验结果,只有正则化比较有用。可见在训练模型时,正则化非常重要!!
【论文笔记】Membership Inference Attacks Against Machine Learning Models (ICMP 2017)