
【论文笔记】Plug & Play Attacks—— Towards Robust and Flexible Model Inversion Attacks(ICMP 2022)
https://zhuanlan.zhihu.com/p/536091331
摘要
关于Model Inversion Attacks(模型反转攻击),即通过利用模型的learned knowledge,从目标分类器的私有训练数据中创造出反映class特征的合成图像。相当于从模型中提取出每种类别特定的特征。这也是很严重安全隐患,因为可能可以提取出如人脸、指纹、身份信息等敏感隐私信息,那么攻击者可以重构人脸,冒用身份……
以前的研究都是训练GAN(生成对抗网络)来作为image priors(先验)。但是存在耗时、耗力、易受数据集分布变化的影响。本文提出的Plug & Play攻击可以减少对image prior的依赖,只需要一个GAN网络即可对大范围的目标进行攻击。而且即使使用的是预训练好的GAN模型、数据分布发生很大变化也可以达到很好的攻击效果。
1 Introduction
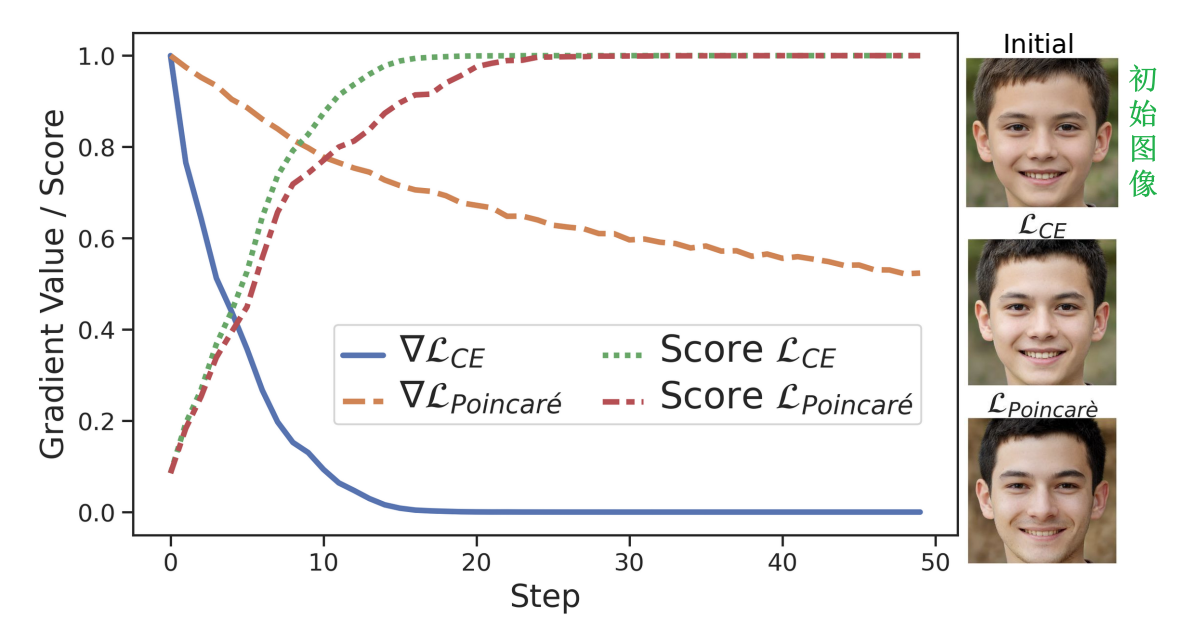
为了解决训练过程中会出现的梯度消失的问题,使用Poincare损失函数,而不是交叉熵损失函数。加入随机转化避免过拟合。首次提出了要从攻击结果中找出有意义的样本的重要性。
2 Model Inversion in Deep Learning
介绍了以前一些攻击方法,及其缺陷。
目前有三种攻击方式:optimization-based, training-based, or architecture-based
optimization-based:通过产生合成的模型输入来找类型特征,也基于梯度下降的方法
training-based:训练GAN模型,将目标模型视作一个加密器,要找解密器
这些都不是为了获取隐私信息,只是探寻目标模型各个类别的特征
可能存在fooling image(无意义的噪点图像),out-of-distribution data(如猫狗分类中出现了一个熊猫图像)
影响因素:distributional shifts, vanishing gradients, and non-robust target models
3 Generative Model Inversion Attacks
定义了理想的MIA攻击,以及会影响MIA攻击效果的因素
假设:目标分类模型为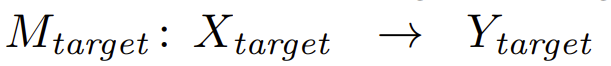 ,且
,且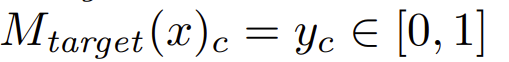 为对x是否为类c∈C的预测分数,敌手可以访问目标模型(作为white box),且无限次地问询,但并不知道C的任何信息。
为对x是否为类c∈C的预测分数,敌手可以访问目标模型(作为white box),且无限次地问询,但并不知道C的任何信息。
敌手要构造一个合成图像x^,满足时目标类别c的特征,泄露了隐私信息。这在较浅的神经网络中可行,但是现在流行的深层神经网络就不行了。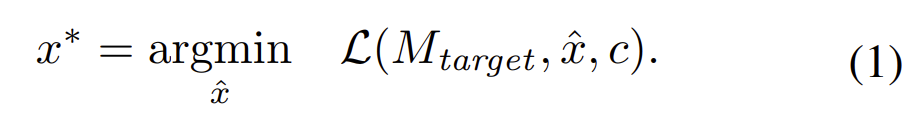
之后产生了使用GAN网络来生成样本(将特征向量z映射到图像空间),并训练鉴别器D来鉴别是否是真实样本x还是由G生成的G(z),得到等式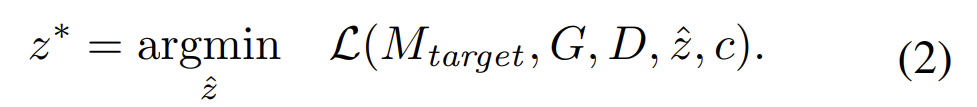 。这样或许可以得到评分($y_c=M_{target}(\overset{\thicksim}{x} )_c$)最高的$ \overset{\thicksim}{x} = G(\overset{\thicksim}{z})$。但是这个构造得到的$\overset{\thicksim}{x}$不一定具有意义。
。这样或许可以得到评分($y_c=M_{target}(\overset{\thicksim}{x} )_c$)最高的$ \overset{\thicksim}{x} = G(\overset{\thicksim}{z})$。但是这个构造得到的$\overset{\thicksim}{x}$不一定具有意义。
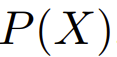 为图像的分布,令
为图像的分布,令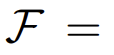
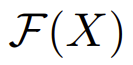 为X中的样本可能具有的人类可识别特征的分布,令
为X中的样本可能具有的人类可识别特征的分布,令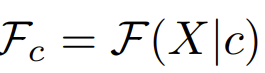 为c类的特征。如再面部图像中,F和P的区别在于,F可能包含发色、皱纹、瞳孔间距等面部特征,而P还多了与身份信息无关的(如服装、背景等)。也就是说,$F$只包含和人物的身份信息有关的信息,而$P$还包含了无用的信息。
为c类的特征。如再面部图像中,F和P的区别在于,F可能包含发色、皱纹、瞳孔间距等面部特征,而P还多了与身份信息无关的(如服装、背景等)。也就是说,$F$只包含和人物的身份信息有关的信息,而$P$还包含了无用的信息。
注意,不同类别之间的特征可能相同。
现假设,有2个类别满足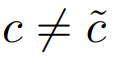 ,且
,且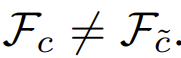 ,即特征不相同。
,即特征不相同。
G可以拟合P(X),进而近似F(X),然后合成符合这个分布的样本x。

【问题】$\overset{\thicksim}{X}$是如何得到的
4 Towards Robust and Flexible MIAs
介绍本文提出的Plug & Play攻击方式。这种方式鲁棒性更好,也更适用于distributional shift setting分布转换设置
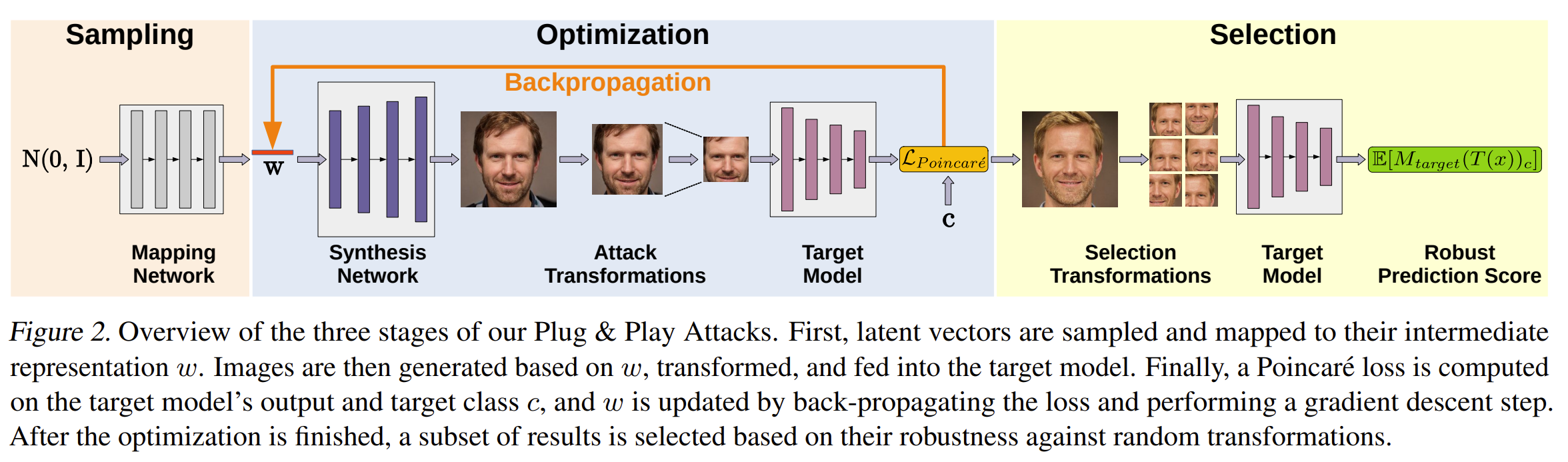
- 首先,latent vectors潜伏向量被采样并映射到它们的中间表征w(用预训练的StyleGAN2模型)
- 然后根据w生成图像,进行转换(Transformations),并输入目标模型。
- 最后,在目标模型的输出和目标类别c上计算Poincare损失,并通过反向传播损失和执行梯度下降步骤更新w。优化完成后,根据其对随机变换的鲁棒性,选择一个结果子集。
4.1. Target-Independent Image Priors
采用预训练的StyleGAN2模型作为图像的先验(不需要辅助输入和训练特定数据集的模型)。只需要是同一领域预训练好的模型。
这里预训练好的StyleGAN2包含2个模块: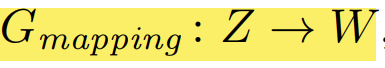 会将随机的latent vector潜伏向量(服从标准正态分布)的z映射到intermediate latent representation中间潜伏向量w。
会将随机的latent vector潜伏向量(服从标准正态分布)的z映射到intermediate latent representation中间潜伏向量w。 则根据w来生成图片
则根据w来生成图片
4.2. Increasing Robustness by Transformations
进行一系列的图像变换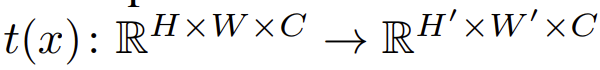 ,并令
,并令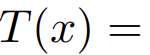
 。在优化过程中,先进行这些可导的图像变换,再输入到目标模型中得到预测分数。即在前向传播过程中计算的是
。在优化过程中,先进行这些可导的图像变换,再输入到目标模型中得到预测分数。即在前向传播过程中计算的是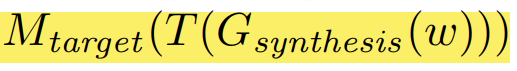
这样,若这些变换后的图像越接近目标分布,攻击就会越成功。而且可以增加生成的图像的鲁棒性
4.3 Overcoming Vanishing Gradients
以前的MIA都基于交叉熵损失函数,这样关于output logit的偏导为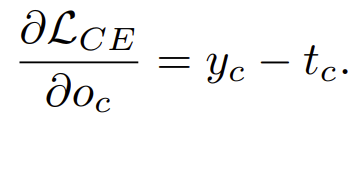 ,容易发生梯度消失。而初始的潜伏向量又是随机产生的,随着调整,其预测分数会越来越高,导致梯度趋于消失。这样如果预先的采样不好的话,由于梯度下降的问题,对初始图像的改动就很小,攻击就会不成功。
,容易发生梯度消失。而初始的潜伏向量又是随机产生的,随着调整,其预测分数会越来越高,导致梯度趋于消失。这样如果预先的采样不好的话,由于梯度下降的问题,对初始图像的改动就很小,攻击就会不成功。
为了解决这个问题,采用Poincaré distance作为损失函数。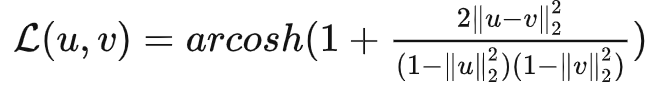 (其中$||·||_2$是欧几里得范数)。它是一个特殊hyperbolic space(双曲空间)中的距离度量。在这个空间里面,一个圆的面积随着半径的增加指数型增加。
(其中$||·||_2$是欧几里得范数)。它是一个特殊hyperbolic space(双曲空间)中的距离度量。在这个空间里面,一个圆的面积随着半径的增加指数型增加。
【注】欧几里得范数即$L2$范数

4.4 Selecting Meaningful Attack Results
选用的方法是transformation-based selection,即通过变换,重新计算得分,选择最高的
攻击结果可能存在误导。本文采取的方法如下:
选取大量的符合正态分布的样本
 ,并映射到intermediate latent space中间隐藏空间$W$
,并映射到intermediate latent space中间隐藏空间$W$为每一个w生成图像
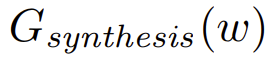 ,并进行剪裁和调整大小的变换。计算平均预测分数,以及horizontally flipped counterpart with $M_{target}$,为每个类别c选择其中得分最高的初始图像。
,并进行剪裁和调整大小的变换。计算平均预测分数,以及horizontally flipped counterpart with $M_{target}$,为每个类别c选择其中得分最高的初始图像。根据蒙特卡罗方法
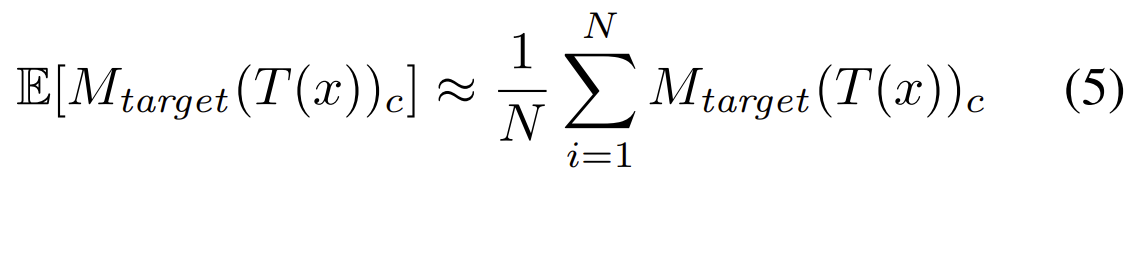
计算预期稳健预测分数,并进行$N=100$次随机的图像变换,选取其中得分最高的50个作为最终攻击结果。【注意】这里选取的变换要和优化过程中选取的不同或更强(否则poorly generated的样本可能会过拟合)
总结
Plug & Play攻击要解决的问题就是:
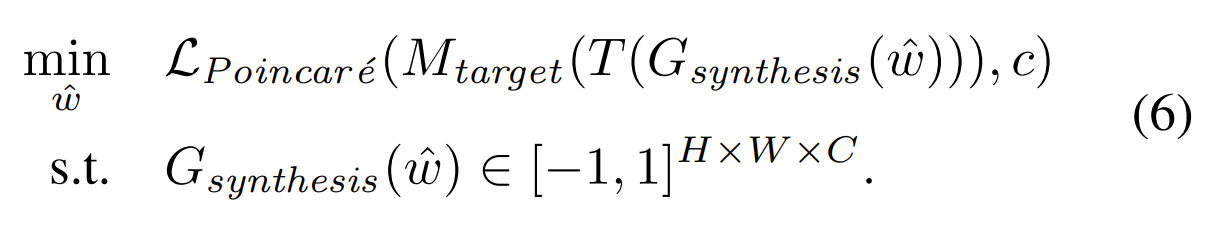
5 Experiments
介绍了验证Plug & Play有效性的实验,和其他攻击方法的对比
评价标准有:
- 在目标模型的数据集上训练Inception-v3模型,然后用该模型对攻击结果进行打分,给出在目标类别上的top-1和top-5准确率。
- 计算平均特征距离$δ_{eval}$,针对面部图像用预训练的FaceNet来测量特征距离$δ_{face}$,越小说明越接近训练数据。
- Fréchet inception distance(FID)
【论文笔记】Plug & Play Attacks—— Towards Robust and Flexible Model Inversion Attacks(ICMP 2022)