
【论文笔记】Reconstructing Training Data with Informed Adversaries(S&P 2022)
摘要&介绍
由于机器学习模型可以有“记忆”功能,那么当训练数据涉及隐私信息时,若被攻击者还原出原始训练数据,就会很危险。这个论文就是探讨这样的攻击是否可能。
所有的训练数据中,只有一个是未知的。目标就是还原出这一个未知的数据样本,找到攻击的方式、泄露多少信息可以达到被还原、哪些特性会导致可还原、自我检查模型的安全性(不泄露信息)
本文提出了一种研究ML模型重构攻击的可行性的通用方法,而无需假设模型的类型或访问中间梯度,并启动了一项能够防止这类攻击的缓解策略的研究
RecoNN一种用于重现数据而训练的神经网络
II. Reconstruction with Informed Adversaries
该部分主要介绍了为什么定义了这样很强的infromed adversaries,即敌手知道除了target以外的所有数据。以及这样的reconstruction攻击和membership inference攻击、attribute inference攻击之间的关系。
III. Reconstruction in convex setting
A. Reconstruction Strategy for Convex Models
针对ERM(经验风险最小化问题)下凸监督学习模型的攻击,在没有side knowledge的时候,对线性回归、岭回归、Logistic回归都可以实现攻击。
若风险函数为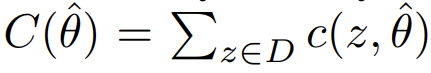 ,且
,且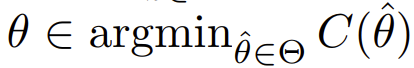 ,则最优解为
,则最优解为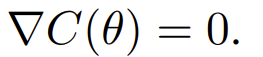
敌手有访问模型的white box(说明知道模型的结构、参数信息),并且有其他所有样本D_ 的信息,那么target z就满足一个方程式
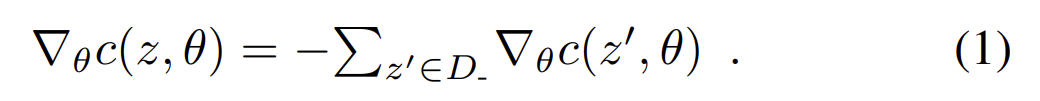
监督学习中一个样本用(x,y)即d维的特征向量x和1维的标签y来表示,则要从d’个等式中解出d+1个未知数(p.s. d’是模型空间的维度)
【解读】为什么是d’个等式?因为模型空间中,每个模型都有一个方程
B. Closed-Form Reconstruction Against GLMs
证明在用截距项拟合的GLM(广义线性模型)的情况下,存在这种攻击的闭式解决方案。

这个攻击下,informed敌手不需要其他关于z的side knowledge
【证明】


IV. A General Reconstruction Attack
针对一般的机器学习(ML)模型的重建攻击
直观上,$z$对模型$θ=A(D_∪{z})$的影响和$\overset{\thicksim}{z}$对$\overset{\thicksim}{θ}=A(D_ ∪\overset{\thicksim}{z})$的影响是一样的,所以可以通过反复尝试来找到$z$
A. General Attack Strategy
记$A_{D_}=A(D_ ∪{z})$,那么当$D_$ 给定时,A就是Z→Θ的函数。那么reconstruction攻击就是要解出$z=A_{D_}^{-1}(θ)$
【注意】这里是一般的ML模型,所以不一定能够保证是convex的,而且模型训练过程中可能有随机性
因为假设了敌手特别强大,所以可以采用枚举的方式,找到最接近θ的
论文中采用的机制是using “neural networks to attack neural networks”,(用魔法打败魔法hhhh),构建了RecoNN模型
B. Training Reconstructor Networks
本文中重构z的步骤如下
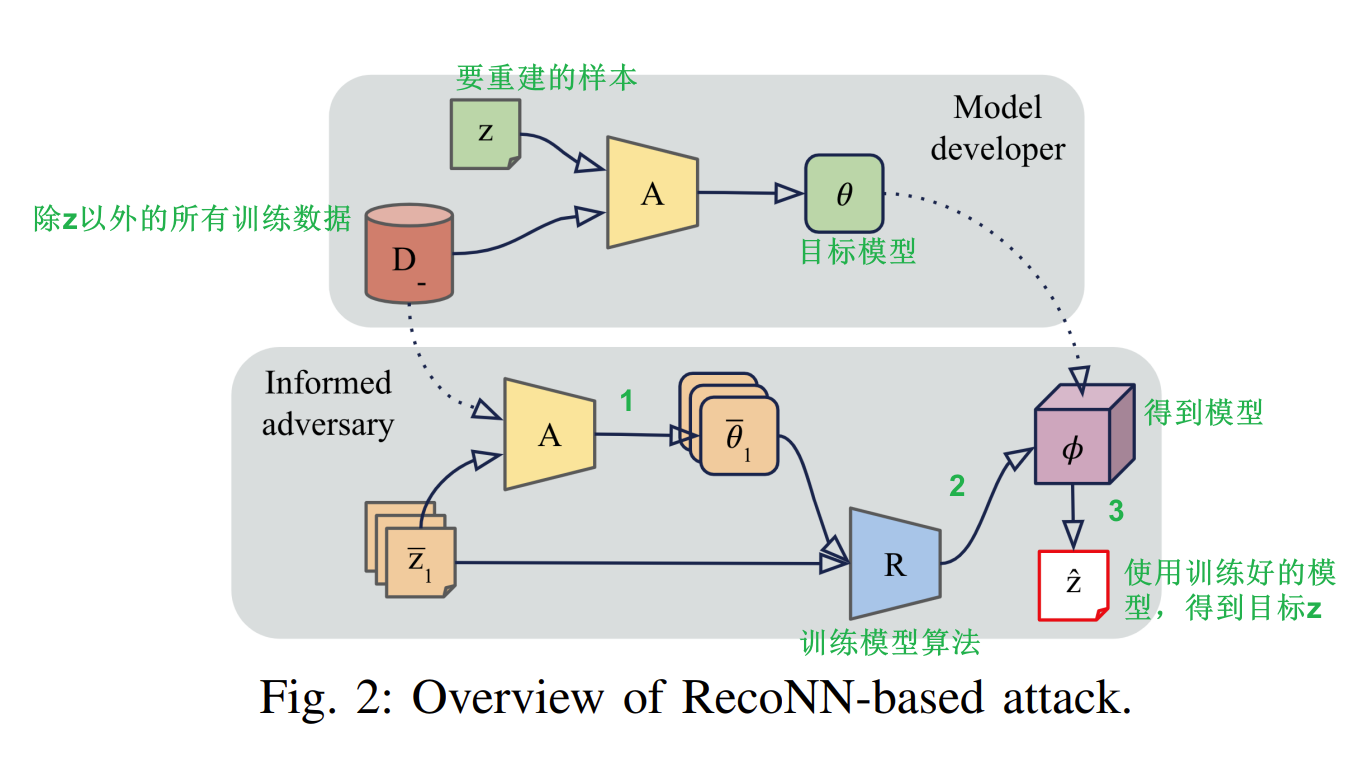
$\bar D=\{\bar z_1,\bar z_2,…,\bar z_k\}$是$Z$中的shadow targets,这属于关于$z$的side knowledge
- 枚举$\bar D$中的所有元素,得到$\bar θ_i$,从而得到了attack training data攻击训练数据
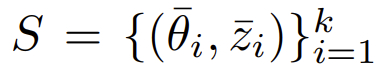
- 使用训练算法R得到RecoNN模型$Φ$
- 应用$Φ$,得到结果$\bar z$
此外,假设了$X$和$Y$都是有限的,且$y$可以从$x$中直接推断出,那么只要重构样本的特征向量$x$即可
具体的训练方式见后面的讨论
using “neural networks to attack neural networks”的相关工作
被应用于了membership inference,model inversion模型反演,property inference
V. Experimental Setup
A. Default Settings
实验中使用的模型的超参数
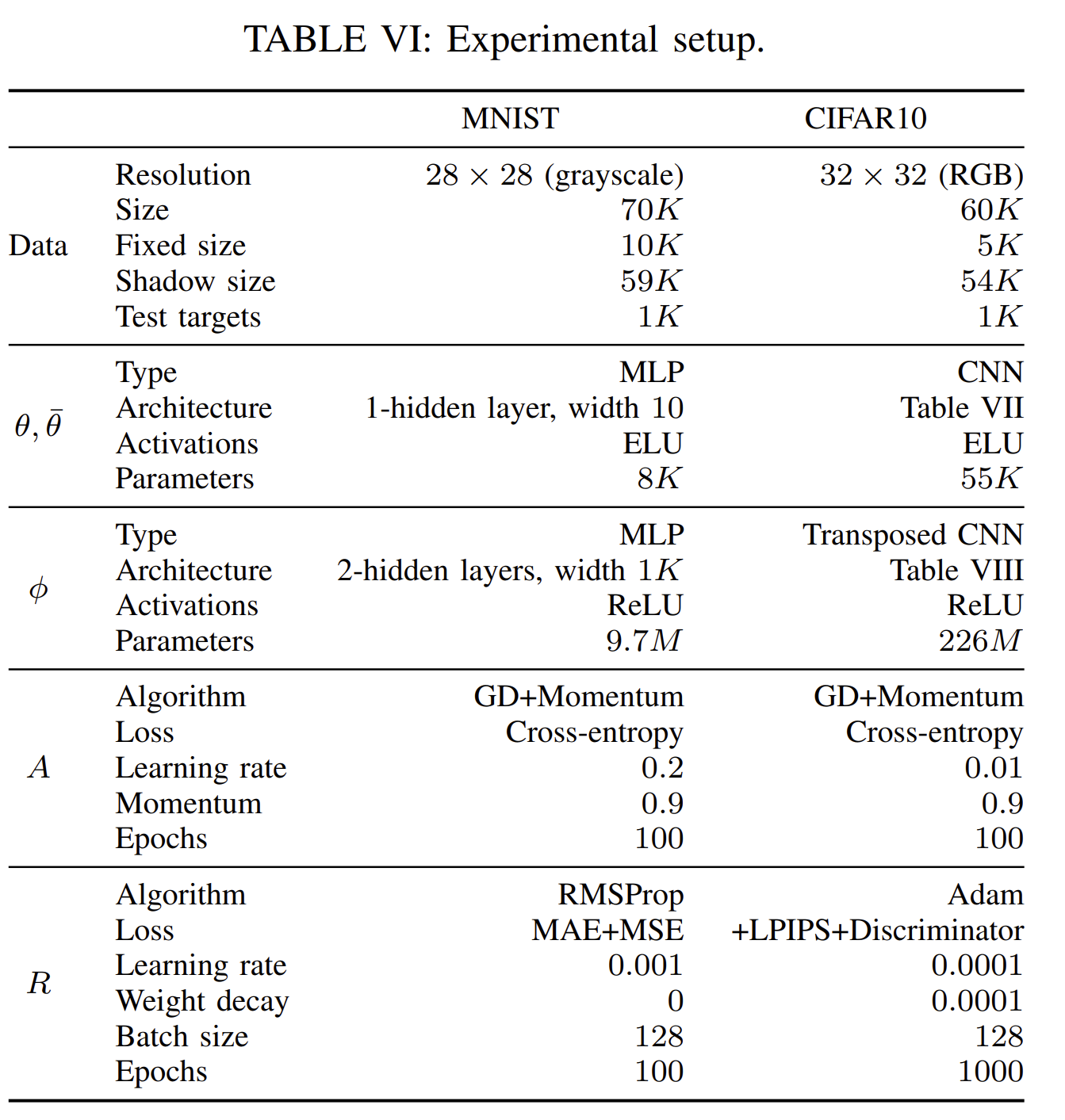
a. 数据集的分割:$D_$、D^和测试目标集是三个不相交的集合
b. 生成模型的训练:训练方式采用的就是标准的梯度下降法,且使用了full batches。假设了敌手直到模型的初始状态,所有模型的初始状态都一致(之后也有讨论使用mini-batching和随机初始化情况下的攻击)
MINST数据集上训练出来的模型准确率更加高(因为CIFAR-10更加复杂),所以对CIFAR-10的攻击可能更加困难,需要更加庞大的shadow points去训练RecoNN
c. 重建模型的训练:When training the reconstructor, shadow model parameters across layers are flattened and concatenated together.???什么意思. 在训练的时候,跨层的参数被扁平化,且连接在一起。还需要把所有的坐标点都缩放到0均值和平均方差,因为有些参数很小。
针对MINST,采用MAE(平均绝对误差)+MSE(均方误差)的方式来计算shadow targets和reconstructor outputs之间的loss。
针对CIFAR-10,增加了LPIPS loss(感知损失)和GAN-like Discriminator loss,都是为了提高图像的视觉质量
B. Criteria for Attack Success
介绍了实验中设置的评估指标
a. MSE:均方差
b. LPIPS:感知损失,即比较深度特征,更加接近人类视觉
c. KL散度:
d. Nearest Neighbor Oracle: 一个oracle,可以猜测离z最接近的点z^
VI. Empirical Studies in reconstruction
总结
采用的策略是针对已知的所有训练数据和shadow targets训练得到的所有模型θ~i~来训练RecoNN模型Φ,来得到θ对应的样本z,即using “neural networks to attack neural networks”
相关知识
membership inference attacks (MIA):成员推理攻击,即判断一个对象是否是模型训练时使用的数据https://blog.csdn.net/xff1994/article/details/89964552
attribute inference attacks (AIA) :推理攻击
property inference attacks (PIA):属性推理攻击,AIA的一种泛化攻击,一般都是得到样本数据的一些属性、平均信息,不会损害个人隐私
GLM广义线性模型:https://zhuanlan.zhihu.com/p/22876460
https://xg1990.com/blog/archives/304
例如线性回归中假设y|x服从正态分布,Logistic回归中假设y|x服从二项分布
canonical exponential family 指数分布族


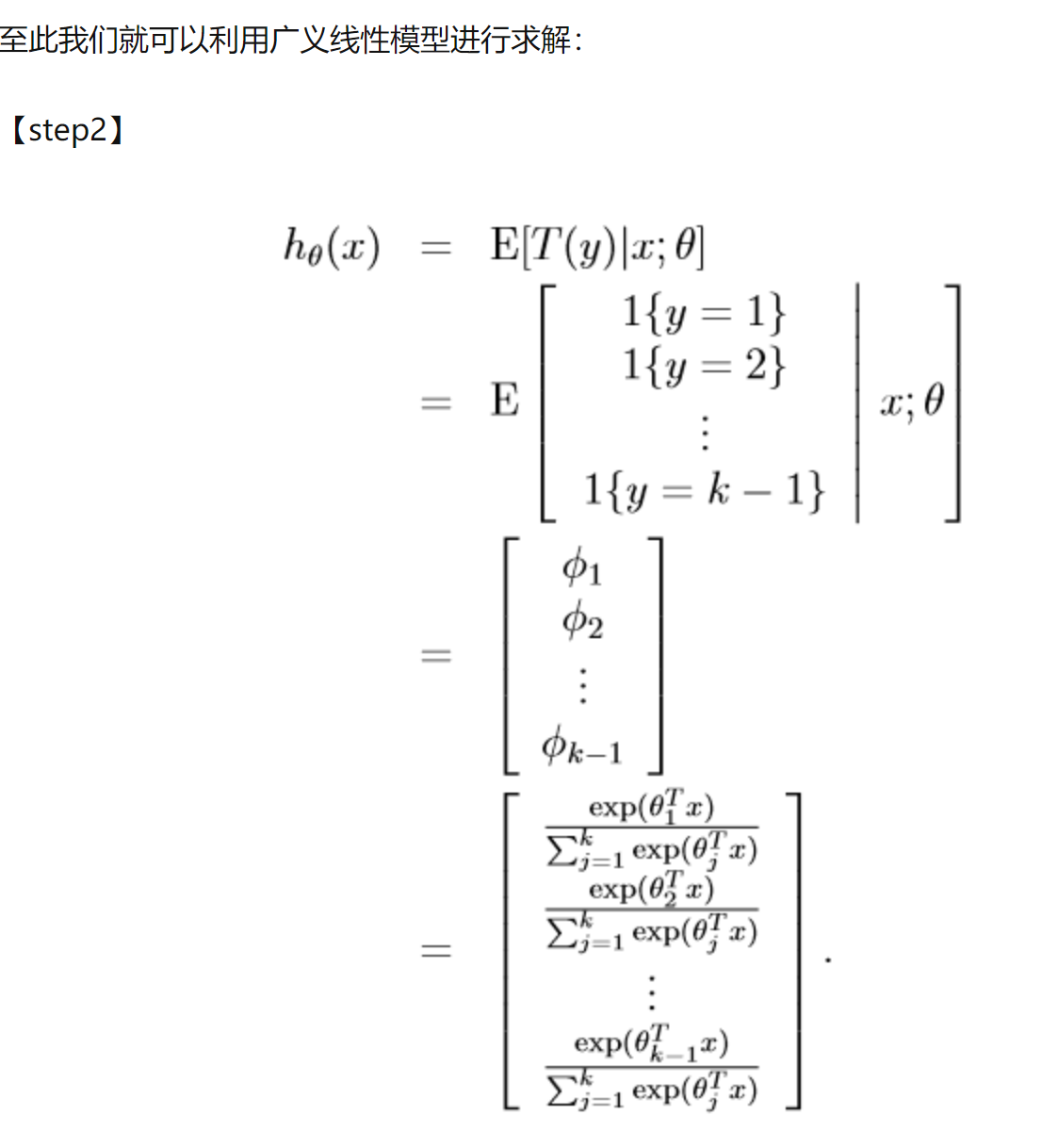
而在GLM中,假设y|x满足这种指数分布族是因为这样下的y|x的期望、方差都非常简单,而要求的目标函数h(x;θ)就是y|x的期望,这样就很简单了。
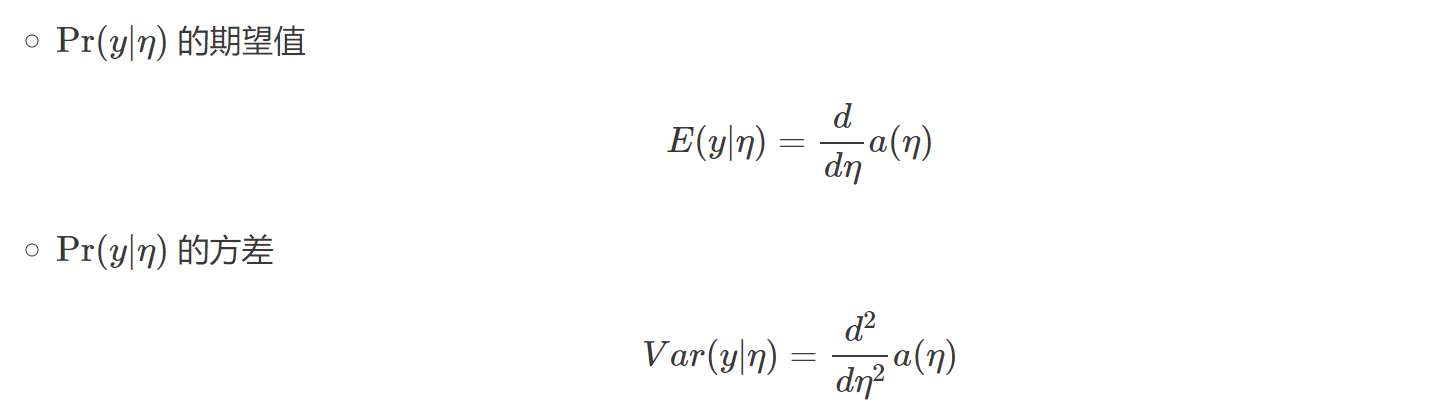
canonical link function 正则关联函数,是canonical response function(正则响应函数)的倒数
LPIPS loss(感知损失):用深度特征来度量图像的相似度
GAN-like Discriminator loss GAN网络(生成对抗网络是要通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布)
问题
没明白”When training the reconstructor, shadow model parameters across layers are flattened and concatenated together.“
扁平化就是说降低维度吧。
【论文笔记】Reconstructing Training Data with Informed Adversaries(S&P 2022)